
Newsletter Subscribe
Enter your email address below and subscribe to our newsletter
Enter your email address below and subscribe to our newsletter

The contemporary conversation surrounding artificial intelligence (AI) and machine learning (ML) is dominated by high-level breakthroughs: large language models passing standardized professional exams, autonomous neural frameworks generating photorealistic cinematic content, and reinforcement learning models mastering complex strategic simulations. Yet, beneath the polished user interfaces of these generative systems lies a rigorous mathematical underbelly. While multi-layered transformers and convolutional topologies receive the public acclaim, the mechanical scaffolding that executes these operations remains rooted in a branch of mathematics formalized in the 19th century: linear algebra. From basic regression architectures to sprawling trillion-parameter deep learning models, vectors, matrices, and tensors are not merely convenient notation—they are the literal computing language of modern AI systems.
In the highly competitive landscape of US higher education and technology sectors, engineering students face a mounting paradox. They are expected to rapidly deploy complex PyTorch or TensorFlow frameworks, yet they frequently stumble over the rigorous multi-dimensional calculations that govern those abstractions. While modern software frameworks abstract these matrix operations away during execution, debugging dimensional errors or optimizing high-throughput training loops requires a deep mathematical understanding. For university students managing both rigorous software development labs and advanced theoretical mathematics, keeping up with these complex multi-dimensional calculations can become an immense bottleneck. When coursework workloads stack up alongside tight deadlines, looking for an external, dependable academic resource to do homework for me can bridge the structural learning gap, allowing future developers to focus on practical framework implementation while maintaining their foundational quantitative workloads.
Key Takeaways
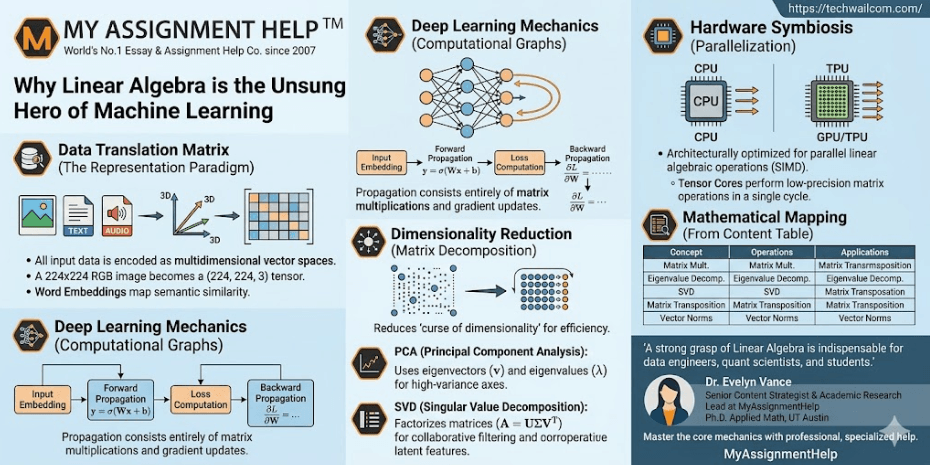
To understand why linear algebra is indispensable to machine learning, one must first examine how a computer perceives information. A neural network cannot natively process a JPEG image, an MP3 audio file, or a string of text. It requires a standardized mathematical abstraction. Linear algebra provides this abstraction via the vector space, allowing complex real-world phenomena to be flattened into deterministic numerical coordinates.
Consider a standard computer vision task. An image is represented as a matrix where each entry corresponds to a pixel’s intensity across specific color channels (Red, Green, Blue). A standard 224 \times 224 pixel image is not treated as a visual asset, but as a tensor of shape (224, 224, 3), yielding 150,528 continuous variables. In natural language processing (NLP), words are transformed into continuous vector spaces via embedding algorithms like Word2Vec or OpenAI’s text-embedding models. These algorithms map textual semantic meaning into a vector space, where semantic similarity corresponds directly to spatial proximity, calculated using the cosine similarity metric:
\text{Cosine Similarity} = \frac{\mathbf{A} \cdot \mathbf{B}}{\|\mathbf{A}\| \|\mathbf{B}\|} = \frac{\sum_{i=1}^{n} A_i B_i}{\sqrt{\sum_{i=1}^{n} A_i^2} \sqrt{\sum_{i=1}^{n} B_i^2}}
Because these multi-dimensional coordinate mapping principles dictate every modern algorithmic model, computational literacy in matrix mechanics is absolutely mandatory for software developers. Yet, navigating these abstract structures requires a profound conceptual shift from standard high-school mathematics. For many American university students, transitioning from scalar arithmetic to complex multi-dimensional space modeling creates a severe learning gap. When vector spaces and coordinate transformation mappings become overly dense, utilizing professional, specialized algebra homework help can offer the structured clarity needed to fully master these essential computer science building blocks.
Inside a deep neural network, the forward propagation pass—the mechanism through which a model generates a prediction—is fundamentally a series of nested matrix multiplications adjusted by non-linear activation functions. Let us look at a single fully connected layer. If an input vector \mathbf{x} passes through a layer defined by a weight matrix \mathbf{W} and a bias vector \mathbf{b}, the layer output \mathbf{y} is computed via the fundamental linear equation:
\mathbf{y} = \sigma(\mathbf{W}\mathbf{x} + \mathbf{b})
Where \sigma represents a non-linear activation function such as the Rectified Linear Unit (ReLU) or Softmax. In a deep neural architecture, this foundational transformation is repeated across dozens or hundreds of sequential layers. The matrix \mathbf{W} structurally controls how the input vector space is rotated, stretched, and shifted to align with the desired target variable spaces.
To maximize mobile-responsiveness and prevent user bounce rates across target platforms, the sequential flow of information through a neural network’s architecture is structured below:
During the model training phase, this optimization engine relies heavily on backward propagation to minimize predictive errors. By structuring these derivatives as gradient matrices and applying the multi-variable calculus chain rule, the algorithm executes highly efficient updates across entire weight layers simultaneously. The mathematical bedrock of this backpropagation cycle is the vector dot product and matrix transposition, which allows the model to map error metrics back to specific underlying network connections.
To illustrate how specific linear algebra frameworks dictate distinct categories of machine learning, the following data table maps mathematical structures to their corresponding algorithmic functions and practical applications within the technology industry:
| Linear Algebra Concept | Core Mathematical Operation | Machine Learning Application | Industry Use Case |
| Matrix Multiplication | \mathbf{C} = \mathbf{A}\mathbf{B} Dot product aggregates | Forward Pass in Deep Neural Topologies | LLM Token Generation (ChatGPT) |
| Eigenvalue Decomposition | \mathbf{A}\mathbf{v} = \lambda\mathbf{v} Characteristic vectors | Principal Component Analysis (PCA) | High-Dimensional Genomic Data Reduction |
| Singular Value Decomposition | \mathbf{A} = \mathbf{U}\mathbf{\Sigma}\mathbf{V}^T Factorization | Latent Semantic Analysis & Collaborative Filtering | Netflix Recommendation Engines |
| Matrix Transposition | \mathbf{A}_{ij}^T = \mathbf{A}_{ji} Dimension inversion | Gradient Alignment during Backpropagation | Weight Optimization Scaling Paradigms |
| Vector Norms | \|\mathbf{x}\|_p = (\sum \|x_i\|^p)^{ Distance scale | L1 (Lasso) and L2 (Ridge) Regularization | Preventing Model Overfitting in Risk Modeling |
Modern commercial datasets routinely feature thousands of variable columns, presenting significant computational hurdles known as the “curse of dimensionality.” High-dimensional data models frequently trigger severe algorithmic overfitting and impose massive processing costs. Linear algebra offers the standard mathematical remedy to this problem through advanced matrix decomposition frameworks, specifically Principal Component Analysis (PCA) and Singular Value Decomposition (SVD).
PCA operates by calculating the empirical covariance matrix of a dataset and evaluating its characteristic roots—known as its eigenvectors (\mathbf{v}) and eigenvalues (\lambda). Mathematically, an eigenvector of a square matrix represents a spatial vector direction that remains unchanged by linear transformations, experiencing only a scale adjustment defined by its corresponding eigenvalue:
\mathbf{A}\mathbf{v} = \lambda\mathbf{v}
In data analytics workflows, the eigenvectors of the data covariance matrix identify the primary axes of maximal statistical variance. By projecting high-dimensional arrays onto the vector space spanned by the top eigenvectors, data scientists can reduce a dataset from thousands of dimensions down to a few critical variables while retaining the vast majority of its underlying structural information. This reduction is vital for deploying real-time predictive systems, such as medical diagnostic software or high-frequency financial modeling engines, where low-latency execution is paramount.
The modern explosion of artificial intelligence is fundamentally a story of hardware optimization. While standard Central Processing Units (CPUs) excel at executing complex, sequential branch logic, they are poorly suited for the massive compute requirements of deep neural networks. Conversely, Graphics Processing Units (GPUs) and specialized Tensor Processing Units (TPUs) are purpose-built to execute massive parallel matrix multiplication operations simultaneously.
A standard CPU core treats data operations sequentially. In contrast, a modern AI-focused GPU contains thousands of compact, specialized arithmetic processing cores designed to execute Single Instruction, Multiple Data (SIMD) pipelines. When a training script fires a matrix multiplication command, the hardware splits the operation into millions of concurrent vector dot products. Tensor Cores—specialized hardware modules developed by Silicon Valley leaders like NVIDIA—perform low-precision matrix multiply-accumulate operations in a single clock cycle. This architectural alignment between mathematical formulas and parallel hardware processing is what transformed deep learning from a fringe academic theory into a major driver of the global technology sector.
As machine learning continues to advance toward artificial general intelligence, the technical frameworks abstraction layers will undoubtedly evolve. High-level software libraries will become more intuitive, and auto-tuning optimization loops will handle more engineering tasks. However, the foundational reliance on linear algebra will remain completely unchanged. Whether engineering next-generation transformer models or designing ultra-efficient edge computing models, the core operations will always reduce to vector transformations and matrix mechanics.
For data engineers, quantitative scientists, and students preparing to enter the US technology workforce, a deep mastery of linear algebra is an invaluable professional asset. Navigating these highly abstract mathematical fields requires more than just memorizing formulas; it demands a comprehensive grasp of vector spaces and coordinate transformation mappings. By building a strong conceptual foundation in these mathematical mechanics, engineers gain the deep insights required to innovate, optimize, and direct the next wave of artificial intelligence infrastructure.
See also: How Smart Devices Are Improving Consumer Convenience
Traditional iterative loops (like for loops in Python) process computational elements sequentially, which creates significant execution bottlenecks. Matrix multiplications utilize optimized vectorization libraries (such as BLAS and LAPACK) running on highly parallelized GPU hardware, executing millions of calculations simultaneously to maximize data throughput.
These terms describe structural data dimensions within a linear algebra framework. A vector is a one-dimensional array of numbers representing a single coordinate point. A matrix is a two-dimensional grid of rows and columns. A tensor is the overarching mathematical term for any multi-dimensional array, encompassing scalars (0D), vectors (1D), matrices (2D), and higher-dimensional data structures (3D+).
SVD factorizes a massive, sparse user-item interaction matrix into low-rank component matrices representing latent preferences and hidden characteristics. By analyzing these compressed vector spaces, platforms like Netflix or Amazon can accurately predict user preferences and generate highly relevant product recommendations in real time.
While standard high-level software abstractions allow developers to import pre-trained models with minimal code, troubleshooting structural errors, optimizing model convergence speeds, customizing specific loss functions, and designing novel neural architectures are completely impossible without a rigorous grasp of the underlying linear algebra transformations.
Dr. Evelyn Vance is a Senior Content Strategist and Academic Research Lead at MyAssignmentHelp. She holds a Ph.D. in Applied Mathematics from the University of Texas at Austin, specializing in computational fluid dynamics and multi-dimensional numerical frameworks. With over a decade of experience bridging the gap between abstract mathematical concepts and production software engineering, Dr. Vance creates advanced data-driven learning resources for computer science and engineering students across the United States.

